

¿Pueden las formas y la distribución de las áreas deforestadas indicarnos sobre los agentes de cambios en la tierra?



Durante la última década ha sido evidente el incremento de la producción de datos geoespaciales relacionados con cambios de uso y cobertura del suelo por parte de los gobiernos y organizaciones de la sociedad civil. Más allá de la valiosa información (ubicación, tasas y valores absolutos) proporcionada por estos conjuntos de datos, es relevante tener una adecuada comprensión de las configuraciones y composiciones espaciales de las áreas de cambio detectadas bajo múltiples resoluciones espaciales y períodos de tiempo. De acuerdo a lo anterior y como parte de su tesis de maestria, Alejandro Coca-Castro investiga los tipos de patrones espaciales de deforestación en el bosque húmedo de la Amazonía a través de la integración de las métricas de fragmentación del paisaje y técnica de minería de datos. La investigación contribuirá a la comprensión de dos conjuntos de datos de deforestación (Terra-i y GFC). Este blog post destaca la metodología de esta investigación, resultados preliminares y desafíos.

Figura 1. Relaciones entre cuatro tipos de patrones espaciales de deforestación, diferenciadas visualmente utilizando Imágenes de Google Earth, con agentes conocidos de uso del suelo. Fotos proporcionadas por el proyecto Terra-i.
Un primera acercamiento a los patrones espaciales de deforestación
Google Maps puede darnos un clara introducción a lo que se refiere con configuraciones espaciales de las coberturas del suelo. Un acercamiento a una región particularmente boscosa como el Amazonas nos permite visualizar diferencias en las formas (composición) y distribución (configuración) entre las áreas deforestadas (Figura 1). Estos tipos de estructuras, comúnmente denominadas como “patrones espaciales de deforestación”, pueden estar relacionados con procesos conocidos del uso del suelo así como agentes que pueden promover perturbaciones en el bosque natural. De esta manera, la identificación y mapeo de estos tipos de patrones de deforestación es clave para proporcionar bajo varios niveles, información flexible para su uso por parte de grupos de conservación de los bosques, los administradores de tierras y profesionales relacionados. Por otra parte, el conocimiento de la configuración espacial y composición de los patrones de deforestación puede fortalecer la modelación de escenarios futuros de uso del suelo.
Metodología: Qué es lo nuevo?
Varias técnicas han sido desarrolladas para facilitar la comprensión de las áreas deforestadas y sus dinámicas en el paisaje (Figura 2). De estos métodos, el análisis de ventana, ha sido ampliamente utilizado no sólo para caracterizar la configuración espacial y la composición de las áreas deforestadas, sino también para determinar los agentes asociados (p.e. pequeños agricultores, grandes plantaciones, pastizales para ganadería, construcción de asentamientos humanos, entre otros). La caracterización de las tipologías de patrones espaciales utilizando análisis de ventana ha sido fuertemente soportada por el desarrollo de software especializado para la evaluación de la fragmentación del paisaje, como el paquete de análisis FRAGSTATS. Este software fortalece el análisis de la estructura del paisaje a través indicadores del paisaje llamados "métricas del paisaje".

Figura 2. Algunos ejemplos de metodologías para el análisis de patrones espaciales y elementos de áreas deforestadas. Para mayor información de cada método consulte las fuentes señaladas en cada figura.
El flujo de trabajo detrás del enfoque de análisis de ventana puede catalogarse dentro de un proceso denominado "Descubrimiento de Conocimiento a partir de Bases de Datos" (abreviado en inglés como KDD) (Figura 3). KDD incluye actividades multidisciplinares que tienen como objetivo la generación de nueva información a partir de bases de datos existentes. Las principales áreas de aplicación están en mercadeo, detección de fraudes, telecomunicaciones y manufactura. KDD abarca el almacenamiento y el acceso de los datos, uso de algoritmos de minería de datos para su aplicación en conjuntos de datos masivos, y la interpretación de los resultados.
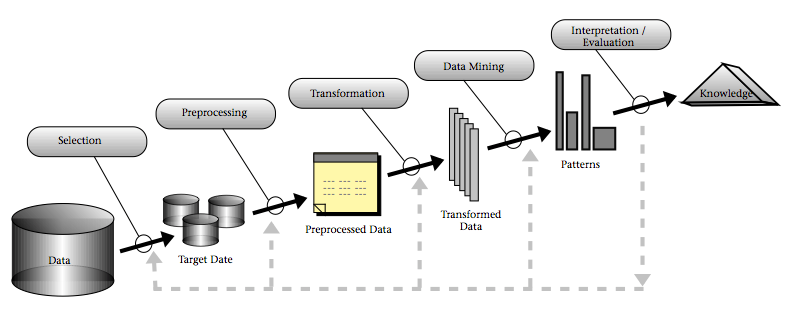
Figura 3. Una visión general de los pasos en procesos de "Descubrimiento de Conocimiento a partir de Bases de Datos" (KDD). Fuente: Fayyad et al. (1996).
En el caso del análisis de patrones espaciales de deforestación bajo el método de ventana, los datos de entrada consisten en una base de datos que contiene registros de las propiedades (métricas) del paisaje. Esto registros son generados de acuerdo a un tamaño de ventana de interes del cual se extraen las métricas del paisaje. Posteriormente, una serie de algoritmos de minería de datos es utilizado para la clasificación automatizada. Aunque la gran mayoría de análisis de patrones ha sido realizado mediante el uso de árboles de decisión, la investigación de Alejandro se centra en la implementación de redes neuronales artificiales debido a su tendencia a ser más robustas que los árboles de decisión. Las redes neuronales artificiales mejoran su desempeño mediante el ‘aprendizaje’, un proceso que puede continuar incluso después de que el conjunto de entrenamiento se ha analizado. Algunas desventajas de las redes neuronales artificiales son las dificultades para explicar su funcionamiento a los usuarios finales (a diferencia de los árboles de decisión, que son fáciles de entender), sobreajuste, o su defecto a converger en la fase de aprendizaje (no garantizan la convergencia u optimización), entre otros.
Aumentando la robustez para el análisis de patrones de deforestación
El algoritmo perfecto para un proyecto KDD no existe; esto depende del contexto del problema y las características de la base de datos. La investigación de Alejandro ha identificado los siguientes pasos claves que pueden mejorar la robustez del proceso de KDD, en este caso para el mapeo de los patrones espaciales de deforestación:
● Pre-procesamiento de los datos de entrada para remover valores perdidos o ruidosos, reducción de las dimensiones de los datos (p.e usando análisis de componentes principales) y/o eliminación de variables altamente correlacionadas o redundantes;
● Uso de técnicas de empaquetado (bagging en inglés) o validación cruzada para entrenar los modelos de redes neuronales artificiales y reducir el sobreajuste;
● Ajuste y prueba de un rango amplio de valores sobre los principales parámetros de redes neuronales artificiales, tales como el número de capas escondidas y descomposición de pesos;
● Selección de los mejores modelos de redes neuronales artificiales de acuerdo a métricas robustas para evaluar el desempeño del clasificador como el Área Debajo de la Curva (en inglés como Area Under the Receiver Operating Characteristic curve (AUC-ROC));
● Graficar en un formato amigable la estructura de los modelos de la redes neuronales seleccionados con el fin de explicar a los usuarios finales como funcionan estos modelos para generar los resultados finales.
Resultados preliminares
La metodología anteriormente explicada fue evaluada en un área piloto (aproximadamente 403.200 metros cuadrados. Kilómetros) en Brasil. En esta área, se consigue ilustrar que tan potentes pueden ser las redes neuronales artificiales para la clasificación de patrones de deforestación.
En este caso, usando una ventana con un tamaño de unos 30 km por 30 km, se creó aleatoriamente un conjunto de datos de entrenamiento, seleccionando 15 cuadrículas representativas (muestras) por patrón (Figura 4).
A partir de este conjunto de datos, se utilizaron 5 muestras para entrenar el modelo. Las muestras restantes (10) fueron por su parte usadas para evaluar el desempeño del modelo. La base de datos de entrada consistió de 113 variables de entrada. Estas variables de entrada fueron las métricas extraídas por cada ventana usando FRAGSTAT a partir de las detecciones agregadas de 2004-2012 del conjunto de datos de Terra-i. Respecto a la estructura de la red neuronal artificial, se definió un conjunto de valores para tres parámetros: el número de neuronas (2 a 40 con un incremento de 5) en la máscara, el parámetro de penalización asociada con la decadencia de peso (0,2 a 0,5 con un incremento de 0,1) y la función de activación (lineal, la entropía o censurado).
Como resultado del proceso de KDD, 423 cuadrículas no etiquetadas se clasificaron automáticamente (Figura 4) con un valor reportado de AUC de 0.65 usando el conjunto de datos de Terra-i. Aunque los resultados fueron prometedores en el área piloto, se encontraron una serie de desafíos para su aplicación en un área de mayor superficie, donde la robustez de la metodología necesita ser probada y evaluada.
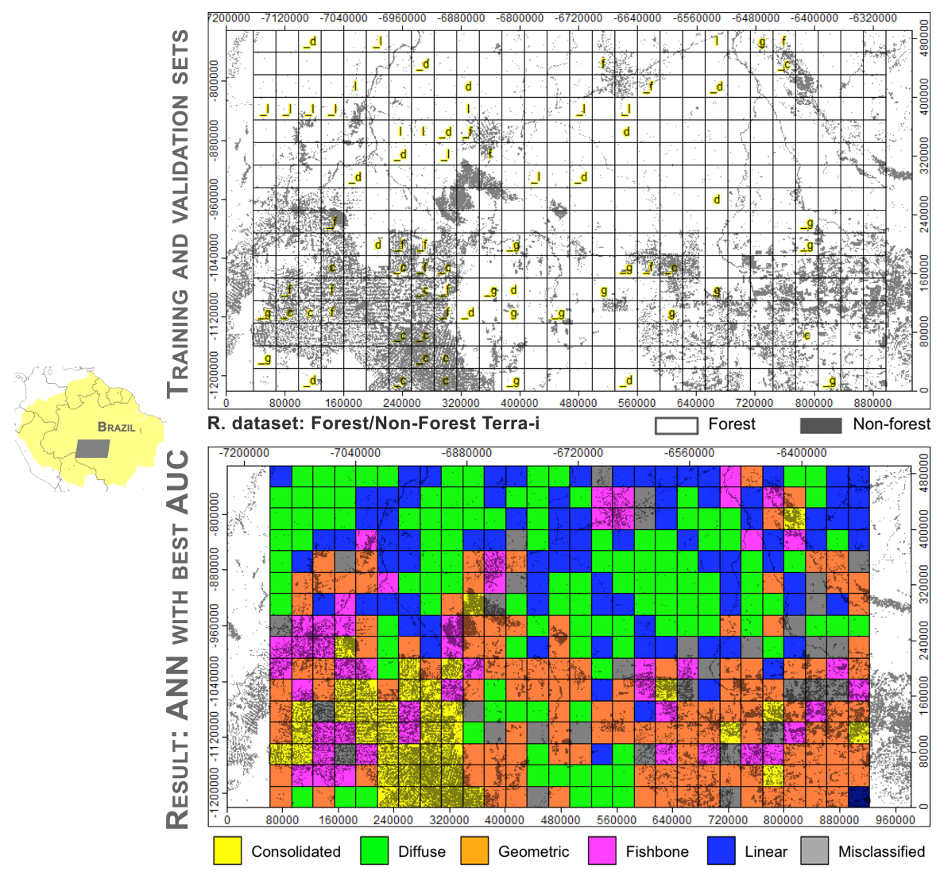
Figura 4. Conjunto de datos de entrenamiento y validación (imágen superior), y resultados (imágen inferior) del modelo de red neuronal que proporcionó el mejor valor AUC para la clasificación de cinco tipos de patrones de deforestación: (c) consolidado, difuso (d), espina de pescado (f), geométrico (g) y lineal (l). En la imágen superior, las letras con o sin el guión bajo indican las muestras usadas para el entrenamiento y validación, respectivamente, por tipo de patrón.
Desafíos
Aunque son varios los desafíos bajo el enfoque descrito, tanto a nivel geoespacial (gestión y pre-procesamiento de grandes conjuntos de datos espaciales) y computacional (manipulación de base de datos y el procesamiento paralelo), los más relevantes desde la perspectiva de la investigación son:
● Evaluación de la influencia de la resolución espacial de los dos conjuntos de datos de deforestación (Terra-i y GFC con 250m y 30m, respectivamente) en los resultados de la clasificación final;
● Identificar y comparar los patrones espaciales de deforestación usando cinco ventanas de tamaños crecientes (8, 15, 30, 60 y 120 km);
● Definición de los modelos óptimos de redes neuronales artificiales a partir de variables de entrada que tengan interpretación ecológica. Esto con el fin de reducir el número de entradas probadas inicialmente en el área piloto (más de un centenar a menos de 30);
● Uso de los modelos de redes neuronales artificiales seleccionados para determinar la dinámica temporal (por intervalos de tres años) de los tipos de patrones espaciales de deforestación por tamaño de la ventana.
Finalmente, en términos de software, esta investigación se basa en el uso de ArcInfo y R, los cuales proporcionan un amplio conjunto de bibliotecas para el análisis espacial y la gestión de bases de datos. El primero permite realizar operaciones vectoriales y raster así como para fines de generacion de mapas finales. El último permite la extracción de las métricas a partir de FRAGSTAT así como realizar procesos de minería de datos utilizando el paquete de R caret .
Alejandro agradece a Mark Mulligan (supervisor de su tesis en el King 's College de Londres) y al equipo de Terra-i por su apoyo, especialmente en la optimización de los aspectos técnicos y de investigación de este trabajo.


IDENTIFICACIÓN DE CAUSAS DE PÉRDIDA DE COBERTURA VEGETAL EN LAS ÁREAS DE INTERVENCIÓN DE LA ACTIVIDAD GOBERNANZA EN ECOSISTEMAS, MEDIOS DE VIDA Y AGUA (USAID/GEMA) EN EL OCCIDENTE DE HONDURAS


MAPEO DE COBERTURAS DE LA TIERRA PARA EL 2017, EN EL OCCIDENTE HONDUREÑO SOBRE ÁREAS DE INTERVENCIÓN DE LA ACTIVIDAD GOBERNANZA EN ECOSISTEMAS, MEDIOS DE VIDA Y AGUA (USAID/GEMA)


CUANTIFICACIÓN DE LA DEFORESTACIÓN EN LAS ÁREAS DE INTERVENCIÓN DE LA ACTIVIDAD GOBERNANZA EN ECOSISTEMAS, MEDIOS DE VIDA Y AGUA (USAID/GEMA) EN EL OCCIDENTE DE HONDURAS


Un equipo internacional de científicos *, en el que participan entomólogos, biólogos de conservación, agroecólogos y geógrafos, acaba de revelar cómo el control biológico de insectos en las granjas puede reducir el ritmo de la deforestación en los trópicos y evitar la pérdida de biodiversidad a macroescala. El caso de estudio se refiere al control biológico de la cochinilla invasora Phenacoccus manihoti con la avispa parásita específica del huésped, Anagyrus lopezi, introducida en el sudeste asiático. Los resultados de este estudio acaban de ser publicados en Communications Biology - Nature.


El CIAT y el equipo Terra-i se complacen en anunciar la publicación de un nuevo estudio en Paraquaria Natural, la más prestigiosa revista científica Paraguaya, dedicada a la biodiversidad y conservación de la naturaleza.


Nuevos focos de deforestación señalan con el dedo a mi fruta favorita. Me encanta Terra-i, pero hoy lo odio mucho. El sistema utiliza imágenes de satélite para hacer un seguimiento de la deforestación en la Amazonía en tiempo casi real. Es muy preciso: si un montón de árboles caen en alguna parte - no importa cuán lejano sea - Terra-i lo detecta. Cool, ¿verdad? Pues hoy no. Louis Reymondin del CIAT, principal arquitecto del sistema, dejó caer la bomba durante el desayuno: parece como si cientos de hectáreas de selva tropical en Perú están siendo destrozados por... papaya.


Ecuador es reconocido por su gran biodiversidad amazónica, sin embargo, justo debajo de ella, yacen las reservas de petróleo del país. Con las grandes compañías petroleras explorando y explotando este recurso subterráneo desde hace más de 45 años, hay apertura de caminos y la subsiguiente atracción de colonos, que van cortando más selva, causando destrucción del hábitat natural. Las detecciones de Terra-i de enero de 2004 hasta febrero de 2015, han revelado una pérdida de hábitat de 87,525 Ha, un área similar a la de la ciudad de Roma. De los cuales, un 19% (16,943 Ha), han sido detectados dentro de áreas protegidas.



El equipo Terra-i junto a CRS El Salvador bajo el proyecto Raíces realizaron un taller virtual a través de la plataforma teams a técnicos del Ministerio de Medio Ambiente y Recursos Naturales, CARITAS, Universidad El Salvador, CENTA, acerca del Mapeo de las coberturas tierra empleando sensores remotos y herramientas de código abierto como GEE, SEPAL y QGIS- Plugin Semi Automatic Classification.


Near real-time vegetation loss detection in Southwestern Ethiopia: calibration, validation, and implementation of the Terra-i system


The Alliance of Bioversity International and the International Center for Tropical Agriculture (CIAT) (the Alliance) conducted a training for local stakeholders on the use of Terra-i as part of the collaboration with the Netherlands Development Organisation – SNV in the Coffee Agroforestry and Forest Enhancement for REDD+ (CAFÉ-REDD) Project.


IDENTIFICACIÓN DE CAUSAS DE PÉRDIDA DE COBERTURA VEGETAL EN LAS ÁREAS DE INTERVENCIÓN DE LA ACTIVIDAD GOBERNANZA EN ECOSISTEMAS, MEDIOS DE VIDA Y AGUA (USAID/GEMA) EN EL OCCIDENTE DE HONDURAS
MAPEO DE COBERTURAS DE LA TIERRA PARA EL 2017, EN EL OCCIDENTE HONDUREÑO SOBRE ÁREAS DE INTERVENCIÓN DE LA ACTIVIDAD GOBERNANZA EN ECOSISTEMAS, MEDIOS DE VIDA Y AGUA (USAID/GEMA)
CUANTIFICACIÓN DE LA DEFORESTACIÓN EN LAS ÁREAS DE INTERVENCIÓN DE LA ACTIVIDAD GOBERNANZA EN ECOSISTEMAS, MEDIOS DE VIDA Y AGUA (USAID/GEMA) EN EL OCCIDENTE DE HONDURAS
Un equipo internacional de científicos *, en el que participan entomólogos, biólogos de conservación, agroecólogos y geógrafos, acaba de revelar cómo el control biológico de insectos en las granjas puede reducir el ritmo de la deforestación en los trópicos y evitar la pérdida de biodiversidad a macroescala. El caso de estudio se refiere al control biológico de la cochinilla invasora Phenacoccus manihoti con la avispa parásita específica del huésped, Anagyrus lopezi, introducida en el sudeste asiático. Los resultados de este estudio acaban de ser publicados en Communications Biology - Nature.


Del 8 al 12 de mayo del 2017 el equipo Terra-i, junto al personal de la DGOTA del Ministerio del Ambiente del Perú, bajo el marco del proyecto “Paisajes sostenibles para la Amazonía” realizaron la primera validación de cambios en la cobertura vegetal monitoreados por Terra-i para las detecciones del 2016 y 2017 utilizando tecnología UAV. Se realizaron sobre vuelos con un drone de rotor Phantom 3 advanced y un drone ala fija Ebee en siete corregimientos de Yurimaguas con el objetivo de conocer las dinámicas de cambios de cobertura y uso de suelo en la región y a su vez validar la precisión de las detecciones de pérdida de bosque monitoreadas por Terra-i en Yurimaguas.
El CIAT y el equipo Terra-i se complacen en anunciar la publicación de un nuevo estudio en Paraquaria Natural, la más prestigiosa revista científica Paraguaya, dedicada a la biodiversidad y conservación de la naturaleza.


El equipo de Terra-i trabajó en la renovación de su sitio web durante este primer semestre, con el fin de brindar a sus usuarios contenidos interactivos y de fácil adaptación a dispositivos móviles. El renovado sitio web se desarrolló usando un administrador de contenidos más actualizado “Magnolia CMS 5.4.4” que les ofrece a los usuarios diferentes categorías de interacción como noticias, datos de cambios en la cobertura vegetal, información, entre otros.


Globalmente más de 1 billón de personas dependen de los bosques para su sustento. Los bosques juegan un papel clave en la regulación del clima, provisión y regulación de servicios ecosistémicos, provisión de agua, almacenamiento de carbono y muchas otras que soportan la biodiversidad. Actualmente la tasa de deforestación global es sustancial por lo que hay la necesidad creciente de información oportuna y espacialmente explícita que permita identificar cambios en la vegetación natural causados por actividades humanas.
Nuevos focos de deforestación señalan con el dedo a mi fruta favorita. Me encanta Terra-i, pero hoy lo odio mucho. El sistema utiliza imágenes de satélite para hacer un seguimiento de la deforestación en la Amazonía en tiempo casi real. Es muy preciso: si un montón de árboles caen en alguna parte - no importa cuán lejano sea - Terra-i lo detecta. Cool, ¿verdad? Pues hoy no. Louis Reymondin del CIAT, principal arquitecto del sistema, dejó caer la bomba durante el desayuno: parece como si cientos de hectáreas de selva tropical en Perú están siendo destrozados por... papaya.


La última actualización de Terra-i se ha utilizado con la herramienta de evaluación de los servicios ecosistémicos Co$ting Nature para comprender los impactos de la pérdida reciente de bosques en Colombia sobre la biodiversidad y los servicios ecosistémicos.
Ecuador es reconocido por su gran biodiversidad amazónica, sin embargo, justo debajo de ella, yacen las reservas de petróleo del país. Con las grandes compañías petroleras explorando y explotando este recurso subterráneo desde hace más de 45 años, hay apertura de caminos y la subsiguiente atracción de colonos, que van cortando más selva, causando destrucción del hábitat natural. Las detecciones de Terra-i de enero de 2004 hasta febrero de 2015, han revelado una pérdida de hábitat de 87,525 Ha, un área similar a la de la ciudad de Roma. De los cuales, un 19% (16,943 Ha), han sido detectados dentro de áreas protegidas.